
Health checks
Configure the container's health checks using the Health Checks tab. Health checks are used to monitor the container's health and determine if the container is ready to serve traffic. Health checks are optional but highly recommended as they help ensure that your application is running correctly and can automatically recover from failures. If no health checks are configured, the container is considered healthy by default if it is running.
Configurations
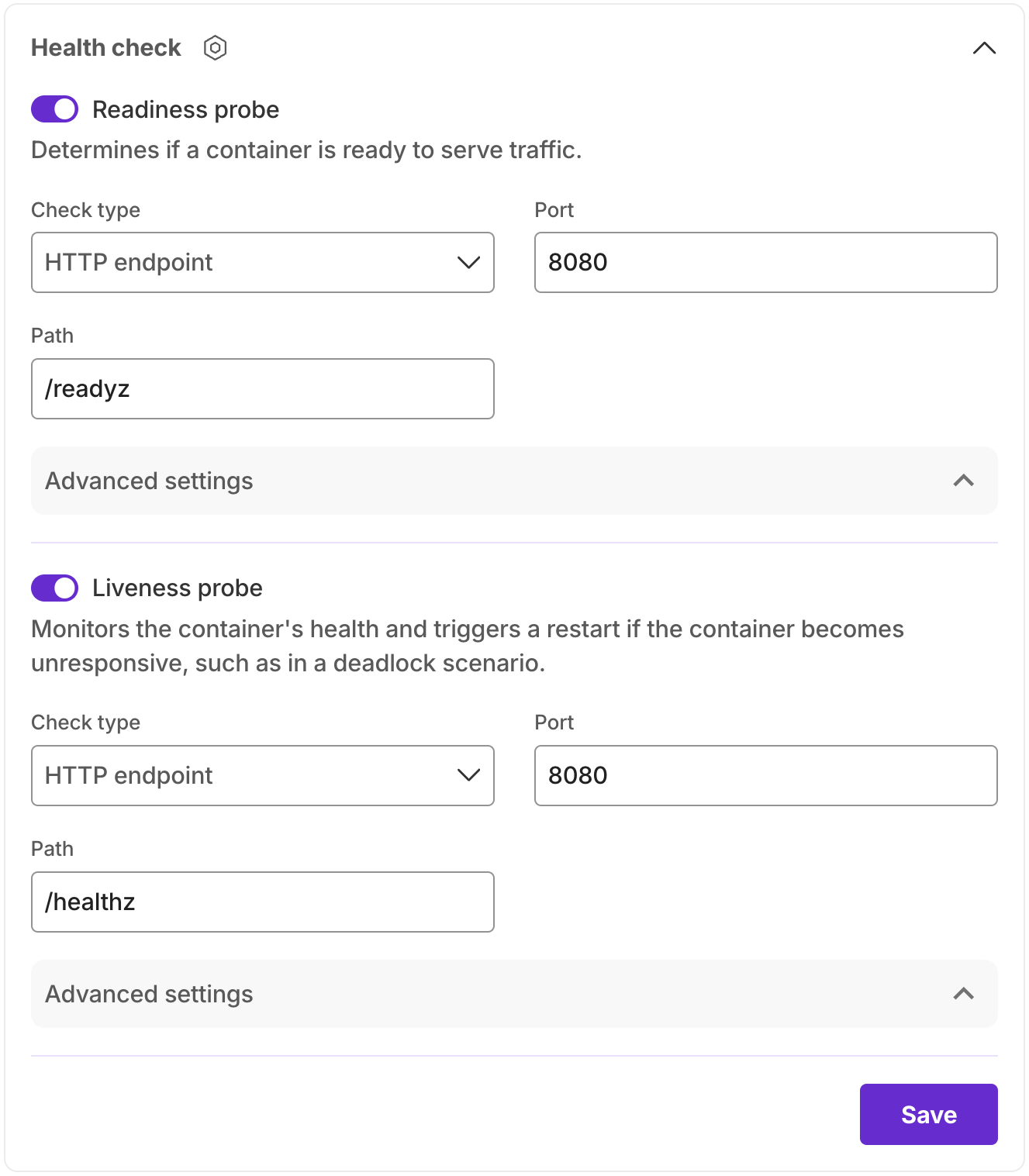
There are two types of health checks:
- Readiness Probe: A readiness probe is used to determine if the container is ready to serve traffic. If the readiness probe fails, traffic is not routed to the container.
- Liveness Probe: A liveness probe is used to determine if the container is still running normally. If the liveness probe fails, the container is restarted.
Health checks can improve the reliability of new deployments since new pods must pass readiness probe checks in order for the deployment to be marked successful. This provides additional assurance that your service will have zero downtime during deployments.
Each check can be configured with the following parameters:
- Probe Type: Choose the type of check you want to perform. The options are:
- HTTP/HTTPS: Perform an HTTP/HTTPS GET request to the specified port and path, the container is considered healthy if the response status code is between 200 and 399.
- TCP Socket: Attempt to open a TCP connection to the specified port, the container is considered healthy if the connection is successful.
- Command: Run a command inside the container, the container is considered healthy if the command exits with a status code of 0.
- Timeout: The amount of time to wait for the probe to complete. If the probe takes longer than this time, it is considered a failure.
- Initial Delay: The time to wait before starting the probe.
- Interval: The time between probe checks.
- Success Threshold: The number of consecutive successful probes required to consider the container healthy.
- Failure Threshold: The number of consecutive failed probes required to consider the container unhealthy.
Use Cases
- Startup processes: If your application requires some time to start up or load data before it can serve traffic, you should configure a readiness probe to ensure that the container is ready to receive requests. While the readiness probe is failing, traffic will be redirected to other healthy containers.
- Long-running processes: If your application is expected to run for an extended period, you should configure a liveness probe to ensure that the container is still running and responsive. This can help prevent the container from becoming unresponsive due to a deadlock or other issue.
- Dependency failure: If your application relies on external services or resources, you should configure a readiness probe to check if those dependencies are available before serving traffic. This can help prevent your application from returning errors due to missing dependencies.
- Traffic throttling: If your application is experiencing high traffic or load, you can use the readiness probe to temporarily redirect traffic to other containers while the overloaded container recovers. This can help prevent the container from becoming overwhelmed and unresponsive.
